
我想了想,还是决定将那篇讲ZAB协议的文章转载过来,ZK中提交事务采用的就是ZAB协议。
转自:http://blog.csdn.net/m_vptr/article/details/9325405
建议还是看原文,我转载到这里利于我查看。向原作者致敬。
ps:个人感觉原博客的一张图画错了,就是那张Leader和Follower的通信图。个人感觉Commit应该是从Leader指向Follower的。
******************************原文如下************************************
ZooKeeper内部有一个in-memory DB,表示为一个树形结构。每个树节点称为Znode(相关的代码在DataTree.java和DataNode.java中)
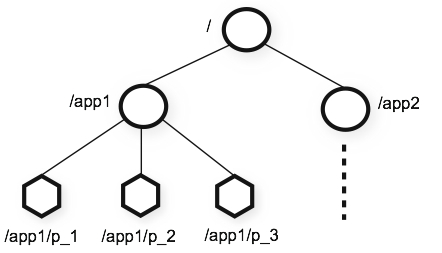
客户端可以连接到zookeeper集群中的任意一台。
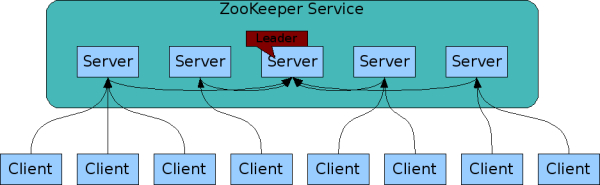
对于读请求,直接返回本地znode数据。写操作则转换为一个事务,并转发到集群的Leader处理。Zookeeper提交事务保证写操作(更新)对于zookeeper集群所有机器都是一致的。
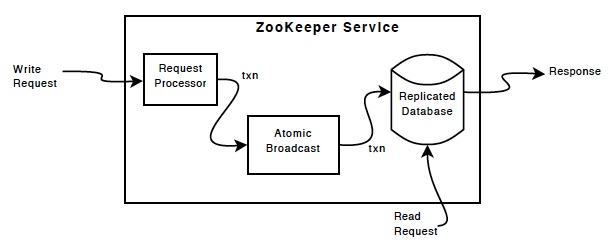
ZooKeeper中提交事务的协议并不是Paxos,而是由二阶段提交协议改编的ZAB协议。
Zab可以满足以下特性
Reliable delivery:如果消息m被一个server递交(commit)了,那么m也将最终被所有server递交。
Total order:如果server在递交b之前递交了a,那么所有递交了a、b的server也会在递交b之前递交a。
Casual order:对于两个递交了的消息a、b,如果a因果关系优先于(causally precedes)b,那么a将在b之前递交。
第三条的因果优先指的是同一个发送者发送的两个消息a先于b发送,或者上一个leader发送的消息a先于当前leader发送的消息。
Zab协议中Server有两个模式:broadcast模式、recovery模式(Leader宕机或follower不构成quorum)
Leader在开始broadcast之前,必须有一个同步更新过的follower的quorum(多数派)。
Server在Leader服务期间恢复在线时,将进入recovery模式,与Leader进行同步。
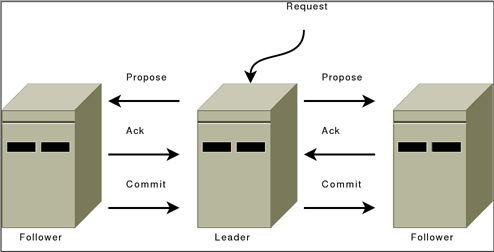
Follower收到proposal后,写到磁盘(尽可能批处理),返回ACK。
Leader收到大多数ACK后,广播COMMIT消息,自己也deliver该消息。
Follower收到COMMIT之后,deliver该消息。
然而,这个简化的二阶段提交不能处理Leader失效的情况,所以增加了recovery模式。切换Leader时,需要解决下面两个问题。
Never forget delivered messages
Leader在COMMIT投递到任何一台follower之前宕机,只有它自己commit了。新Leader必须保证这个事务也必须commit。
Let go of messages that are skipped
Leader产生某个proposal,但是在宕机之前,没有follower看到这个proposal。该server恢复时,必须丢弃这个proposal。
新Leader在propose新消息之前,必须保证事务日志中的所有消息都proposed并且committed。
为了保证follower看到有proposal,以及递交的消息,Leader向follower发送follower没有见过的PROPOSAL,以及最后提交的消息的编号之前的COMMIT。
因为Proposal是保存在follower的事务日志中,并且顺序有保证,因此COMMIT的顺序也是确定的。解决的第一个问题。
上个没有把proposal发送出去的Leader重启后,新Leader将告诉它截断事务日志,一直截断到follower的epoch对应的最后一个commit位置。
关于ZAB的详细证明可以参考Zab - High-performance broadcast for primary-backup systems



相关推荐
NULL 博文链接:https://supben.iteye.com/blog/2094077
前面虽然配置了集群模式的Zookeeper,但是为了方面学建议在伪分布式模式的Zookeeper学习Zookeeper的shell命令。Zookeeper支持某些特定的四字命令字母与其的交互。他们大多数是查询命令,用来获取Zookeeper服务的当前...
该资源内有三个xmind脑图文件,分别为Hadoop,hbase ,以及分布式协调zookeeper选举的基础知识内容。该脑图内容并不是非常详细,而是大体罗列了这三个技术的框架,适合初学者以及将要面试,复习的同学。通过脑图,...
大数据框架组件 含Hadoop、Spark、Flink等大数据书籍 ...三、Hive 1.Hive——Hive概述 2.Hive——Hive数据类型 3.Hive——Hive DDL数据定义 4.Hive——Hive DML数据操作 5.Hive——Hive查询
大数据学习路线 大数据技术栈思维导图 大数据常用软件安装指南 一、Hadoop 分布式文件存储系统:HDFS 分布式计算框架:MapReduce 集群资源管理器:YARN 单机伪集群环境搭建 集群环境搭建 常用 Shell 命令 Java API ...
本资料是提供给 dubbo 入门者的,技术高手请不要浪费钱财。...本资料旨在提供最单纯的 dubbo 学习和入门,摒弃了所有非必要的技术,对于dubbo 的入门和理解很有帮助,但对于 dubbo 的深入学习是没有用的。
第二部分 ZOOKEEPER学习 24 第6章 zookeeper介绍 25 6.1 zookeeper简介 25 6.2 分布式应用程序 25 6.3 Apache Zookeeper意味着什么? 26 第7章 zookeeper基本组成与工作流程 27 第8章 zookeeper的leader节点选择 31 ...
它通常具有以下三个特征: 数据量大:大数据指的是数据集的规模非常庞大,远远超出了传统数据处理工具的能力范围。这些数据集可能包含数十亿甚至数万亿的记录。 复杂度高:大数据往往包含多种类型和格式的数据,...
毕业设计是高等教育阶段学生在完成学业前所进行的一项重要学术任务,旨在检验学生通过学习所获得的知识、技能以及对特定领域的深刻理解能力。这项任务通常要求学生运用所学专业知识,通过独立研究和创新,完成一个...
三、适用人群与场景 无论您是初学者还是资深开发者,无论您是在校学生还是职场人士,本系列资料都将是您学习SSM的得力助手。适用于Java Web开发、企业级应用开发、个人项目实践等多个领域。 四、使用建议 系统...
最近在学习Kafka,准备测试集群状态的时候感觉无论是开三台虚拟机或者在一台虚拟机开辟三个不同的端口号都太麻烦了(嗯。。主要是懒)。 环境准备 一台可以上网且有CentOS7虚拟机的电脑 为什么使用虚拟机?因为使用...
3)Zookeeper学习 Zookeeper分布式协调服务介绍。 Zookeeper集群的安装部署。 Zookeeper数据结构、命令。 Zookeeper的原理以及选举机制。 第⼆阶段(攻坚阶段) 4)Hadoop (《Hadoop 权威指南》)---80⼩时 HDFS ...
本书是中国云计算专家委员会刘鹏教授主编的系统讲解云计算技术的专业书籍,重点阐述了云计算领域具代表性的Google、亚马逊和微软三个三家公司的云计算平台的技术原理和应用方法,并介绍了以Hadoop为代表的开源云计算...
其优点是学习成本低,⼤数据学习kou群74零零加【41三⼋yi】可以通过类SQL语句快速实现简单的 MapReduce统计,不必开发专门的MapReduce应⽤,⼗分适合数据仓库的统计分析。 本模块通过学习 Hive、Impala 等⼤数据 ...
本文介绍了一种用于大规模深度学习ADS系统的分布式GPU分级参数服务器。我们提出了一种利用GPU高带宽内存、CPU主存和SSD作为三层分层存储的分层工作流。所有的神经网络训练计算都包含在GPU中。对真实数据的大量实验...
大数据学习路线 大数据技术栈思维导图 大数据常用软件安装指南 一、Hadoop 分散文件存储系统 —— HDFS 多元计算框架——MapReduce 集群资源管理器 —— YARN Hadoop单机伪集群环境搭建 Hadoop 云服务环境搭建 HDFS...
现在网上有关详细系统的Zookeeper教程合并,于是自己想着来写一个,其实也是结合官方英语文档进行学习,计划将覆盖Zookeeper配置使用,结合Java实现一些案例,代码解释,以及最终与dubbo等进行结合部署一个分布式...
毕业设计是高等教育阶段学生在完成学业前所进行的一项重要学术任务,旨在检验学生通过学习所获得的知识、技能以及对特定领域的深刻理解能力。这项任务通常要求学生运用所学专业知识,通过独立研究和创新,完成一个...